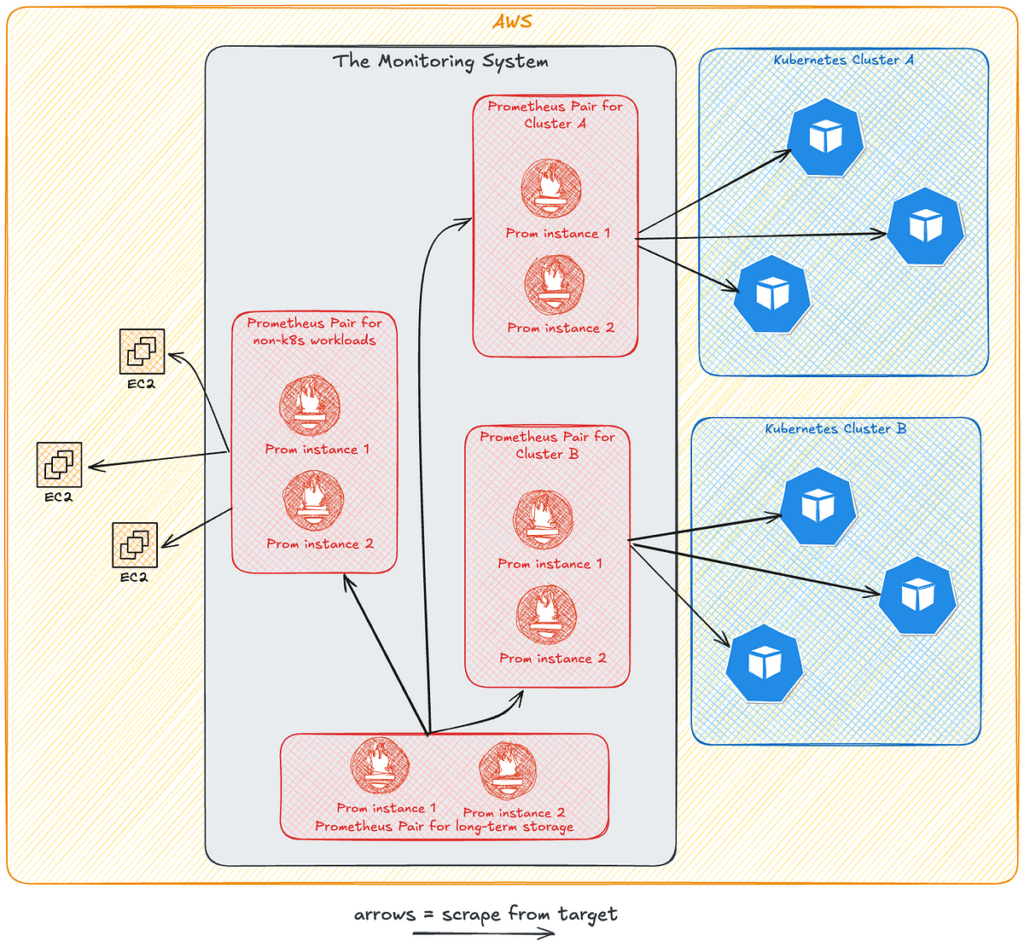
By 2024, Prezi’s monitoring system, built around Prometheus, was becoming outdated. It was already 5+ years old, running on a deprecated internal platform and accumulating a significant amount of costs every month.
At the beginning of the year, we decided to deal with the “future problem” and modernize our metrics collection and storage system. Our goals were to run the monitoring system in our Kubernetes-based platform and reduce the overall complexity and costs of the system.
We achieved these using VictoriaMetrics. This post describes our journey, the challenges we faced, and the results we achieved from the migration.
Our Prometheus-based system wasn’t that problematic by itself — we ran a pair of instances, to achieve high availability, for each of our Kubernetes cluster. We also had one extra pair for non-Kubernetes resources, and one for storing a subset of metrics with longer retention. You can see the high-level architecture of the system in the diagram below.
Just before the migration, we had 5 Million active series at any given point in time. It’s also worth noting that our microservices ecosystem was already instrumented for producing metrics in Prometheus format, and it was something that we didn’t want to change — it’s at this stage de-facto the standard (although it is slowly becoming superseded by OpenTelemetry).
There are some challenges when operating such a system:
- Exploring metrics or configuring rules must target specific installations. This made dashboarding and alerting more difficult, and it already is difficult for most non-SRE folks in general.
- The instances Prometheus ran on had to be really beefy to handle our load.
- As mentioned in the introduction, the instances were running on the previous version of the Prezi platform that was already deprecated. We really wanted to move off.
Now that you know what we were dealing with, let’s look at what we could have done with it. We set out to explore our options, considering both managed and self-hosted solutions. We quickly realized that we couldn’t afford to ship our metrics to any of the vendors out there. We would have to spend at least 2x the current cost, and, the perspective of modern self-hosted solutions being even cheaper, led us to drop that path.
On the self-hosted end of the spectrum, we had:
- Thanos
- Mimir/Cortex
- VictoriaMetrics
Some members of the team were already familiar with Thanos and Cortex, so these were the biased first-choice tools that we first tried to understand. But we didn’t stop there and made a complete comparison for the concerns that we cared about. You can see the table from one of our exploration documents below.
We initially thought that using block storage may be a downside of VictoriaMetrics. Nothing more wrong — while it’s tempting to use the infinitely-scalable object storage (like S3), the good old block storage is just cheaper and more performant. Given that cost control was one of the priorities, we saw an opportunity to run the system cheaper, and quite possibly — with less complex architecture. For example, thanks to using block storage, VictoriaMetrics no longer needs any external cache subsystem, as is the case with the other two.
In the process of exploring what VictoriaMetrics has to offer, we also took a small detour and talked with the good folks at VictoriaMetrics to see if buying an Enterprise license for self-hosting, which enables some features that we could have wanted, is within our budget. Turns out we didn’t really need these features, but buying the license wouldn’t break the bank for us either. And, there’s nothing wrong with asking for a quote!
VictoriaMetrics stood out thanks to its simplicity and cost-efficiency, which we tested in a Proof of Concept.
We jumped into the implementation of a small proof-of-concept system based on VictoriaMetrics, to see how easy it is to work with (what’s good from the most cost-effective system if you can only get there after 3 months of tuning it back and forth?), how it performs, and to extrapolate the cost of the full system later on.
VictoriaMetrics allows you to install VictoriaMetrics Single — all-in-one, single executable, which acts almost exactly like Prometheus. It can scrape targets, store the metrics, and serve them for further processing or analysis. We knew from the start that we wanted to use VictoriaMetrics Agents to scrape targets, as that allowed us to host a central aggregation layer installation and distribute the agents — all of them contained, collecting metrics only within their environments (be that Kubernetes cluster, or AWS VPC).
The initial idea
We wanted to host the tool on Kubernetes at the end, so it made sense to rely on the distributed version of the system— for high availability and scalability, it just sounded good. We took the off-the-shelf helm chart for the clustered version — one, where VMInsert, VMStorage, and VMSelect are each separate components.
The concept is fairly simple — VMInsert is the write proxy, VMSelect is the read proxy, and VMStorage is the component that persists the data to underlying disks. On top of that, we also installed VMAlert — the component used for evaluating rules (Recording and Alerting).
We didn’t want to test agent options yet
We initially used Prometheus servers with remote_write for testing but quickly found that VictoriaMetrics Agents were far more performant for our needs. Even though we had a lot of headroom on the instances, the Prometheus was just too slow to write to VictoriaMetrics.
Installing VictoriaMetrics Agent was easy with the already existing scraping configuration. We simply replicated the configuration — that was enough to make the Agent work.
The cost and the performance
We managed to create a representative small version of the system. That allowed us to test the performance of reads and writes, and see how much resources (CPU time, Memory, and storage size) the system used. We were absolutely delighted. We found queries that were timing out after 30 seconds in Prometheus, returning data in 3–7 seconds in VictoriaMetrics. We didn’t find any queries that were performing significantly worse.
We also found that the resource usage footprint was minimal. The data is efficiently stored on the disk, and compressed, and the application uses very little CPU time and Memory. Our estimations at the time showed: 70% less storage, 60% less memory, and 30% less CPU time used. This, together with bin-packing in Kubernetes made us excited about saving a significant amount of money spent on the system.
Well done, VictoriaMetrics!
Too good to be true, or how using Availability Zones can empty your wallet
So it was working, and it was working well. We were scraping metrics and using remote_write to store them. We could query the metrics in Grafana (added as Prometheus data source, because VictoriaMetrics’ MetricsQL, the query language, is a superset of PromQL — which is fantastic!), we even added some alert rules and saw them trigger. That was so smooth. Too smooth.
A couple of days later, we found that we had accumulated a significant amount of dollars, which was attributed to the network traffic in our environment. Turns out that running a distributed metrics system, where each time you query or write a metric, you get an extra hop (VMSelect or VMInsert to VMStorage), can be costly when you put that in the context of inter-zone traffic in your hyperscaler (AWS for us). Not only were typical metric writes and reads subject to that , but evaluating rules (and we have some really heavy recording rules) also used the same route. That was concerning and made us stop and rethink our approach.
We needed to figure out something else.
Back to the roots
If you scrolled up to the previous state diagram, where I showed how we used Prometheus, you might see that we used a pair of instances for HA. We decided to keep that approach for our new system. Instead of using the clustered version of VictoriaMetrics per Availability Zone, we tested the installation based on two separate VictoriaMetrics Single instances, each in a different AZ. We went into “save as much as possible mode” at that time, and we traded local redundancy for a global redundancy — since a single cluster with distributed components would be enough for us, reliability-wise — two instances in a hot-hot setup would also do it!
Installing two single-replica Deployments of VictoriaMetrics Single worked flawlessly for us (spoiler — it still does work flawlessly more than a half year later 🚀). We no longer cross Availability zones with our extra hop traffic.
We added a pair of VictoriaMetrics Alert instances next to each VictoriaMetrics Single instance, operating in the same Availability Zone.
We set up a load balancer in front of the instances for reading the metrics, mainly used by Grafana. Occasionally, one of the VMSingle instances goes down — then the traffic is sent to the other one. When the instance is unavailable, we don’t lose data — agents buffer it, and while we may skip a couple of recording rules evaluations, VictoriaMetrics provides a neat way to backfill rules using vmreplay.
The only time the traffic goes across AZs now is when an agent is not hosted in the same zone as the target VictoriaMetrics Single instance. This is something that can not be worked around, as long as we want two agents to write the data (which is then deduplicated smartly by VictoriaMetrics).
Finally, our architecture looked like below:
(Yes, the diagram looks a bit more convoluted than the diagram for the previous system. This is the price you pay for having a more-performant and cost-effective system with a better user experience 🙃)
There are also other use cases, which I haven’t touched on above — the long-term storage, and using VictoriaMetrics Operator to scrape non-Kubernetes and improve system configuration capabilities. I want to expand a bit on these and one extra special thing below.
Long-term storage
We also wanted to migrate our long-term storage installation of Prometheus. When exploring VictoriaMetrics, using an enterprise license to have different retention configurations for series was tempting, but we checked and it wasn’t the most cost-effective way to do it.
We also had a brief episode of sending these metrics to Grafana Cloud, where we have 13 months of retention. That cost us pennies, but at the time of adding it, we had two Grafana installations — self-hosted, and Cloud instance.
Having both short-term and long-term metrics in one Grafana would require us to add the Grafana Cloud Prometheus data source in our self-hosted instance. That’s nothing, but we found something better — we just set up yet another VMSingle instance with a different retention setting. We not only pay even less but have 100% of metrics in our infrastructure.
VictoriaMetrics Operator
Our scraping and rules configuration for the previous system was overly complicated, with a baggage of tech-debt — neither we nor our users understood how to configure the system, sometimes. We wanted to change that.
We chose to install and configure VictoriaMetrics using the Kubernetes Operator. All of the components are managed by the Operator, as well as the configuration of the system. That allowed us to distribute the configuration concerns to our users — our product teams can now configure alerting for their services from their repositories. If you want to know how we pulled that off, let me know — that would definitely be material for another post.
Scraping non-Kubernetes resources with VictoriaMetrics Operator
When we were setting up the system in production, VictoriaMetrics Operator was still in its early days. There was no support for Service Discovery of non-Kubernetes targets (now there is one), and there was no way to install VMAgent (Operator-managed Custom Resource) that wouldn’t be injected with the same configuration as the other VMAgents in the cluster (at least not an easy, maintainable way).
To overcome these and still collect metrics from our other workloads, we chose to install an additional VictoriaMetrics Agent using the helm chart and configure it statically. This works for us because the targets don’t change that much and are mostly infrastructure-related, so the people configuring the scraping are more familiar with Prometheus/VictoriaMetrics than, say, a Python-focused Software Engineer.
Single pane of glass in Grafana Cloud with self-hosted metrics
Lastly, the very recent change that is worth mentioning — consolidating our Grafana instances. We now have only one instance of Grafana, thanks to a smart solution offered by Grafana Labs — Grafana Private Data Connect. We install the agent next to our VictoriaMetrics, which sets up a SOCKS5 tunnel between our and Grafana Labs’ infrastructure. That allowed us to add a self-hosted VictoriaMetrics as a data source in Grafana Cloud. What’s more — it’s free (except for the network traffic)! Neat! Well done, Grafana Labs! 💪
Note: We are a happy customer of Grafana Labs and their Cloud offering, as you may know from How Prezi replaced a homegrown Log Management System at Medium or Grafana’s Big Tent Podcast S2E2, where Alex first explained how we landed on Grafana Loki for our Log Management, and then explained how we use Grafana IRM for our Incident Management. Check these out!
The benefits can be summarized as follows:
- Cost Efficiency: Saved ~30% on system costs.
- Performance: Query speeds improved significantly, with heavy queries completing in 3–7 seconds (vs. 30+ seconds).
- User Experience: Streamlined metrics access and configuration via Kubernetes-native tools.
- Scalability: The system is now future-proof for growing workloads.
Lastly, working on the migration allowed us to learn a ton, and work on something interesting and challenging.
Migrating from Prometheus to VictoriaMetrics transformed our monitoring system, offering cost savings, performance gains, and an improved developer experience. If you’re considering a similar move, we strongly recommend evaluating VictoriaMetrics for its simplicity and efficiency.

